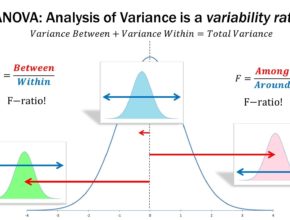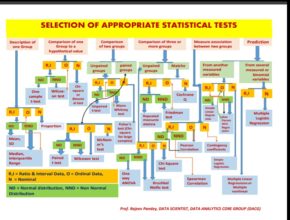
Artificial Intelligence / Data Analysis / Fundamentals of Statistics / Machine Learning / Predictive Analytics / SPSS
COVID-19 Dataset and its description
Day level information on COVID-19 affected cases From World Health Organization – On 31 December 2019, WHO was alerted to several cases of pneumonia in Wuhan City, Hubei Province of China. The …
Read More