Machine learning teaches computers to do what comes naturally to humans and animals: learn from experience. Machine learning algorithms use computational methods to “learn” information directly from data without relying on a predetermined equation as a model. The algorithms adaptively improve their performance as the number of samples available for learning increases.More Data, More Questions, Better Answers:
Machine learning algorithms find natural patterns in data that generate insight and help you make better decisions and predictions. They are used every day to make critical decisions in medical diagnosis, stock trading, energy load forecasting, and more. Media sites rely on machine learning to sift through millions of options to give you song or movie recommendations. Retailers use it to gain insight into their customers’ purchasing behavior.
Real-World Applications:
With the rise in big data, machine learning has become particularly important for solving problems in areas like these:
• Computational finance, for credit scoring and algorithmic trading
• Image processing and computer vision, for face recognition, motion detection, and object detection
• Computational biology, for tumor detection, drug discovery, and DNA sequencing
• Energy production, for price and load forecasting
• Automotive, aerospace, and manufacturing, for predictive maintenance
• Natural language processing
How Machine Learning Works: 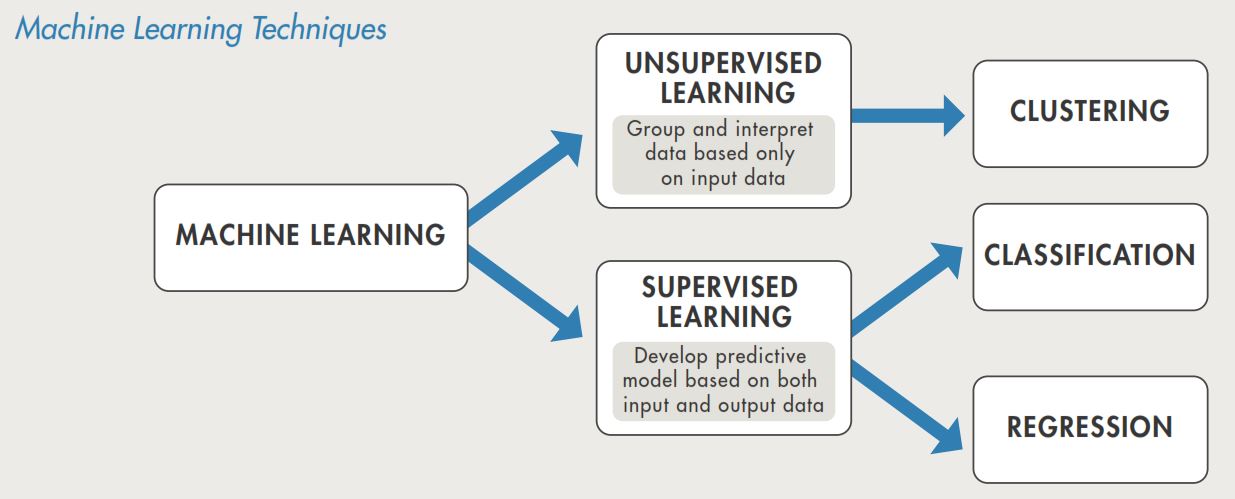
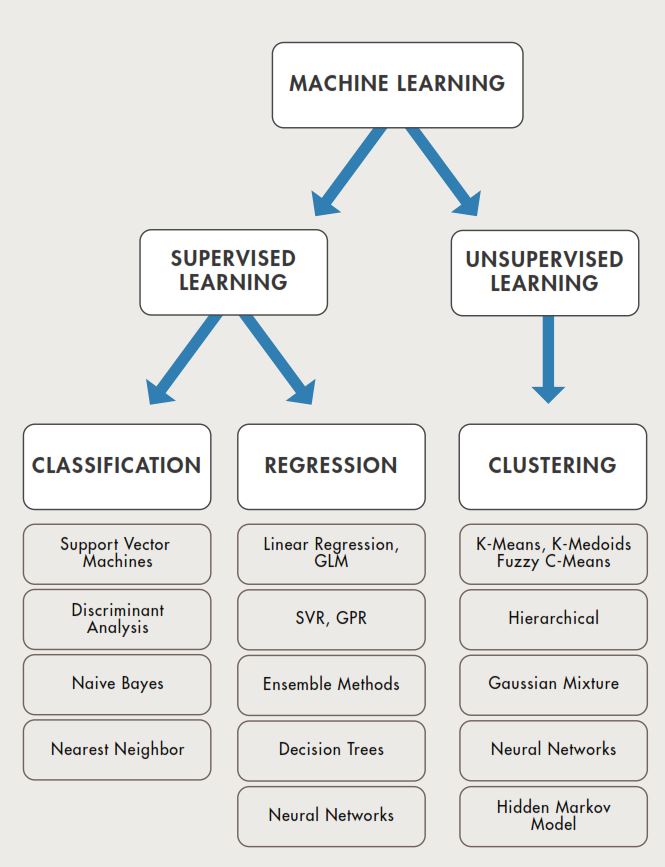
Supervised Learning:
The aim of supervised machine learning is to build a model that makes predictions based on evidence in the presence of uncertainty. A supervised learning algorithm takes a known set of input data and known responses to the data (output) and trains a model to generate reasonable predictions for the response to new data.
Supervised learning uses classification and regression techniques to develop predictive models.
• Classification techniques predict discrete responses—for example, whether an email is genuine or spam, or whether a tumor is cancerous or benign. Classification models classify input data into categories. Typical applications include medical imaging, speech recognition, and credit scoring.
• Regression techniques predict continuous responses— for example, changes in temperature or fluctuations in power demand. Typical applications include electricity load forecasting and algorithmic trading.
Unsupervised Learning:
Unsupervised learning finds hidden patterns or intrinsic structures in data. It is used to draw inferences from datasets consisting of input data without labeled responses.
Clustering is the most common unsupervised learning technique. It is used for exploratory data analysis to find hidden patterns or groupings in data.
Applications for clustering include gene sequence analysis, market research, and object recognition.
How Do You Decide Which Algorithm to Use?
Choosing the right algorithm can seem overwhelming—there are dozens of supervised and unsupervised machine learning algorithms, and each takes a different approach to learning.
There is no best method or one size fits all. Finding the right algorithm is partly just trial and error—even highly experienced data scientists can’t tell whether an algorithm will work without trying it out. But algorithm selection also depends on the size and type of data you’re working with, the insights you want to get from the data, and how those insights will be used.